


Le brief IA #50
La « singularité douce » selon Sam Altman.

🔥 Actualités
1. La « singularité douce » de Sam Altman : vers quel futur de l’IA ?
Heureuse révolution ou utopie technologique ? Résumé et analyse d’une vision qui divise.
Altman est persuadé qu’on a déjà franchi le « point de bascule » vers une IA surhumaine. Dans The Gentle Singularity, il anticipe une montée en puissance continu : dès 2025, les agents accompliraient de vrais travaux cognitifs (programmation avancée, documents complexes) et en 2027 des robots exécuteraient des tâches physiques.
L’IA pourrait accroitre de manière significative la recherche et la productivité : « Les gains de qualité de vie liés à l’IA (progrès scientifiques accélérés, productivité accrue) seront immenses ». Les « merveilles technologiques » deviendraient rapidement banales, « on passe d’être impressionné par un paragraphe superbe généré par l’IA à se demander quand elle écrira un roman, ou guérira une maladie », selon lui, la singularité se déroule ainsi, étape après étape. Il imagine déjà qu’en 2030, intelligence et énergie seront « follement abondantes », abolissant leurs limites historiques. En pratique, on décuplera la productivité individuelle (un ingénieur 2030 produira dix fois plus qu’en 2020).
Altman décrit des boucles vertueuses (« flywheels ») : les valeurs économiques générées par l’IA financeront la construction de nouvelles infrastructures.
Robots fabriquant d’autres robots.
Datacenters finançant d’autres datacenters.
L’IA servira l’IA, rendant le progrès exponentiel.

Il prévoit même qu’à terme le coût du calcul convergera vers celui de l’électricité.
Grâce à ces mécanismes, il imagine un monde où « les ordinateurs nous aideront à trouver des avancées scientifiques encore plus vite », ouvrant la voie à des découvertes impensables (interfaces cerveau-machine, colonisation spatiale, etc.).
Selon lui, l’adaptation sociale interviendra sans heurt : les humains trouveront toujours de nouvelles activités utiles, les emplois évolueront et le monde, beaucoup plus riche, permettra d’expérimenter de nouveaux contrats sociaux.
Altman pose ses conditions pour réussir cette singularité. Il affirme qu’il faut en priorité « résoudre le problème de l’alignement », garantir que les IA servent vraiment les valeurs humaines à long terme, puis « rendre la superintelligence bon marché, largement disponible et décentralisé.
Ce que révèle ce discours venant du PDG d’OpenAI
Quand Sam Altman s’exprime sur le futur de l’IA, ce n’est pas un exercice théorique. C’est un acte de positionnement politique, économique et technologique.
Sam Altman est à la tête d’une entreprise à qui l’on a confié des dizaines de milliards, soutenue par Microsoft, en position centrale dans la course à l’AGI.
Sa vision de la « singularité douce » sert donc plusieurs objectifs simultanés :
Désamorcer la peur, en proposant une narration rassurante.
Légitimer un rythme rapide de développement, en montrant qu’il s’agit d’une dynamique naturelle, presque inévitable.
Ancrer OpenAI comme leader de cette transition, malgré les controverses internes récentes.
Ce n’est pas anodin. Un discours calibré depuis cette position de pouvoir oriente les imaginaires, influence les régulateurs, façonne les attentes des investisseurs et balise le terrain concurrentiel.
Ce que ça révèle de l’alignement et des risques
Derrière le ton confiant, la question du contrôle des IA reste centrale. Altman reconnaît lui-même que sa firme n’a pas encore toutes les réponses sur l’alignement.
Il propose une stratégie incrémentale : augmenter les capacités tout en testant et corrigeant à chaque étape. Mais ce pari soulève de vraies inquiétudes :
Le désalignement n’a pas besoin d’être malveillant : un objectif mal formulé peut mener à des comportements catastrophiques.
Aucun consensus scientifique n’existe aujourd’hui sur la manière de garantir qu’une superintelligence poursuivra les bons objectifs.
Certains experts pointent la contradiction entre discours prudent et choix industriels : démantèlement d’équipes “Safety”, priorisation du produit et du CA au détriment de l’investissement sur l’alignement.
La vraie question devient donc : peut-on construire un système plus intelligent que nous sans avoir de méthode robuste pour le contrôler ?
Ce qu’il faudrait construire et surveiller
D’abord, la recherche en sécurité de l’IA. Il faudra augmenter largement l’effort pour créer des mécanismes de contrôle (tests de robustesse, vérification formelle, etc.) qui garantissent que les IA se comportent comme prévu. Cela nécessite davantage de collaboration ouverte (partage des méthodes de sécurité), et idéalement des audits indépendants de la part d’institutions publiques.
Ensuite, la gouvernance et la régulation. L’un des plus grands risques est la concentration du pouvoir technologique. Altman plaide pour un accès démocratisé mais aujourd’hui quelques entreprises (OpenAI/Microsoft, Google, Meta, Alibaba, etc.) dominent l’IA. Il faut donc construire dès maintenant des organes internationaux (traités, normes communes, panels d’experts) pour surveiller ces développements.
Enfin, l’interface société-humains. Une transition profonde s’annonce : refonte du marché du travail, régulation fiscale des entreprises IA, requalification massive des compétences, ou même réflexion sur la redistribution (revenu universel, etc.). Altman laisse entendre qu’un « nouveau contrat social » sera pensé petit à petit, mais ces choix ne seront pas automatiques. Il faudra inventer des politiques adaptées (protéger les emplois vulnérables, développer l’éducation à l’IA…) pour accompagner l’essor de l’IA dans la vie quotidienne.
2. Nouveaux modèles / outils
Mistral
Magistral
Mistral AI dévoile Magistral, son tout premier modèle spécialisé en raisonnement. Deux versions sont disponibles : Magistral Small (open source, 24B paramètres) et Magistral Medium (version entreprise). Le modèle brille sur des benchmarks comme AIME2024 et fonctionne en plusieurs langues, avec une capacité native à raisonner en français, arabe, chinois, etc. Il est optimisé pour des applications complexes (recherche juridique, prévision financière, dev, etc.) et peut répondre jusqu’à 10x plus vite via "Flash Answers" dans Le Chat.

Mistral compute
Mistral lance Mistral Compute, une offre complète d'infrastructure IA. Cette plateforme propose un stack privé (GPU, orchestration, API, services) déployable en bare-metal ou en PaaS, avec un focus sur la souveraineté, la durabilité et l’alternative aux géants du cloud US/Chine. Pensée pour les États, entreprises et labos, elle s’appuie sur l’expertise interne de Mistral en HPC et IA, et sur un partenariat avec NVIDIA. L’objectif : permettre à chacun, notamment en Europe, de bâtir et posséder son propre environnement IA.
")
Google
Gemini 2.5
Google élargit la gamme Gemini 2.5 avec la sortie générale de 2.5 Pro et 2.5 Flash, désormais stables pour les applications en production. Ils annoncent aussi 2.5 Flash-Lite, en preview : c’est leur modèle le plus rapide et le plus économique à ce jour. Il surpasse la version 2.0 sur les benchmarks en code, raisonnement, science et multimodalité, tout en conservant un contexte de 1 million de tokens et les fonctionnalités avancées (outils, exécution de code, budgets adaptatifs). Idéal pour les tâches volumineuses et sensibles à la latence.

Meta
V-JEPA 2
Meta présente V-JEPA 2, un modèle de type world model (pas un LLM) conçu pour comprendre, prédire et planifier des actions dans le monde physique. Avec 1,2B de paramètres, il atteint des performances SOTA sur des tâches comme la reconnaissance d’actions et la planification robotique en zero-shot. Le modèle est pré-entraîné sur plus d’un million d’heures de vidéos, puis affiné avec 62h de données robotiques. Meta publie aussi trois nouveaux benchmarks (IntPhys2, MVPBench, CausalVQA) pour évaluer le raisonnement physique à partir de vidéos, et pousse la recherche vers des agents capables de simuler et anticiper le monde comme les humains.
Letta
Letta introduit des agents vocaux à mémoire persistante, combinant le naturel des interfaces vocales avec la puissance des agents, tools et mémoire. Grâce à une architecture optimisée (Sleep-time Voice), Letta gère le contexte conversationnel via des bases de données, compresse intelligemment les échanges, et exécute des tools en parallèle pour maintenir une latence <1s, même sur de longues discussions.
3. En vrac :
Apple met l’IA dans vos apps, vos appels, vos photos… mais pas encore dans Siri
Copyright vs IA : Disney et Universal déclarent la guerre à Midjourney
🤖 Ressources data science et machine learning
1. Abstract Classes: A Software Engineering Concept Data Scientists Must Know To Succeed
Cet article explique pourquoi les classes abstraites sont un outil essentiel pour structurer proprement les pipelines data science. L’auteur illustre leur utilité via un exemple concret : un pipeline de nettoyage de données pour alimenter une pipeline de feature engineering. En définissant une classe abstraite de base, on impose une structure commune à tous les projets, tout en laissant la flexibilité nécessaire pour gérer les spécificités client. L’approche permet de rendre le code plus lisible, maintenable, réutilisable, et robuste aux erreurs humaines, un vrai gain de qualité pour les équipes data en contexte industriel.
2. Regularisation: A Deep Dive into Theory, Implementation, and Practical Insights
Un guide super complet sur les techniques de régularisation qui mêle intuitions mathématiques, exemples concrets, implémentation Python. Cet article vous permettra de mieux comprendre pourquoi et quand appliquer chaque technique, avec code à l’appui si vous voulez tester.

🧑🔬 Ressources deep learning et LLMs
1. How we built our multi-agent research system
Anthropic partage un retour d’expérience rare : comment ils ont conçu, testé et mis en production un système multi-agent pour des tâches de recherche complexes.
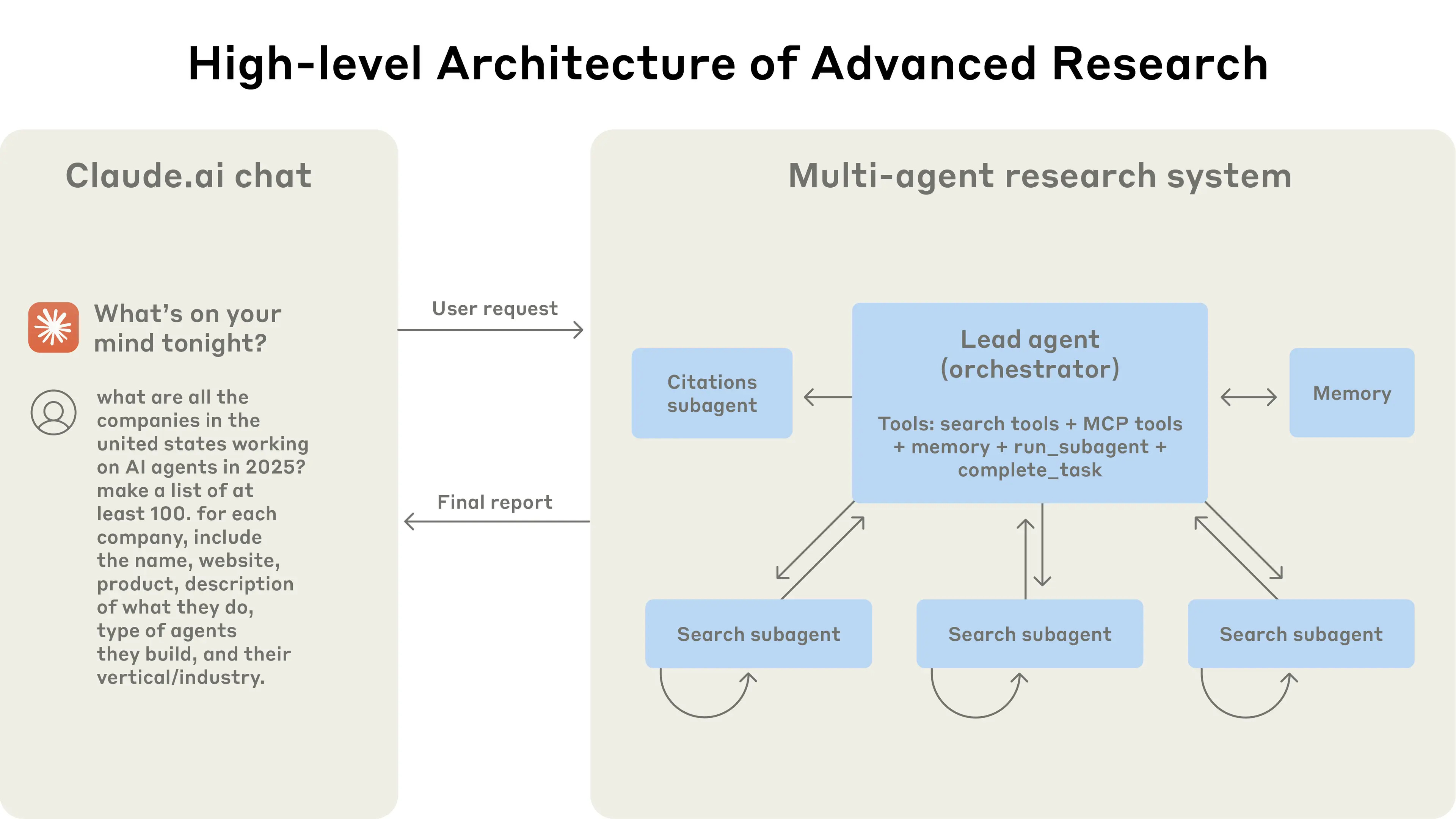
Le billet aborde les vrais sujets : coordination entre agents, design des outils, évaluation, gestion des erreurs, scalabilité… sans masquer les pièges rencontrés.
Très intéressant
🔌 Ressources MLOps
1. MCP vs API
MCP, c’est pas “encore une API”. Et si vous vous demandez pourquoi, ce post met les choses à plat.
Frank Fiegel y clarifie ce qui distingue fondamentalement MCP des APIs classiques, et pourquoi ça change la façon dont on pense l’intégration des agents IA dans des systèmes complexes.
À lire si vous bossez sur des architectures orientées agents ou si vous êtes curieux. Il y a une vidéo YouTube qui détaille les éléments.
🛠️ Outils
1. Dia browser
Un outil un peu différent cette fois : Dia Browser, développé par la même entreprise à l’origine d’Arc Browser. Les deux produits se veulent distincts, ne s’adressent pas au même public, et je dois dire que je suis assez séduit par cet outil. Il propose une expérience de navigation centrée sur l’IA, avec un assistant conversationnel intégré directement dans l’omnibox (la barre d’adresse). Dia adopte une interface plus classique, proche d’un Chrome épuré.
📖 Papiers
This study explores the neural and behavioral consequences of LLM-assisted essay writing. Participants were divided into three groups: LLM, Search Engine, and Brain-only (no tools). Each completed three sessions under the same condition. In a fourth session, LLM users were reassigned to Brain-only group (LLM-to-Brain), and Brain-only users were reassigned to LLM condition (Brain-to-LLM). A total of 54 participants took part in Sessions 1-3, with 18 completing session 4. We used electroencephalography (EEG) to assess cognitive load during essay writing, and analyzed essays using NLP, as well as scoring essays with the help from human teachers and an AI judge. Across groups, NERs, n-gram patterns, and topic ontology showed within-group homogeneity. EEG revealed significant differences in brain connectivity: Brain-only participants exhibited the strongest, most distributed networks; Search Engine users showed moderate engagement; and LLM users displayed the weakest connectivity. Cognitive activity scaled down in relation to external tool use. In session 4, LLM-to-Brain participants showed reduced alpha and beta connectivity, indicating under-engagement. Brain-to-LLM users exhibited higher memory recall and activation of occipito-parietal and prefrontal areas, similar to Search Engine users. Self-reported ownership of essays was the lowest in the LLM group and the highest in the Brain-only group. LLM users also struggled to accurately quote their own work. While LLMs offer immediate convenience, our findings highlight potential cognitive costs. Over four months, LLM users consistently underperformed at neural, linguistic, and behavioral levels. These results raise concerns about the long-term educational implications of LLM reliance and underscore the need for deeper inquiry into AI's role in learning.
Merci d’avoir lu Le brief IA !