


Le brief IA #49
Apple remet l’église au centre du village.

🔥 Actualités
1. The Illusion of Thinking : quand les modèles “raisonneurs” plafonnent
Apple publie une étude qui démonte une croyance qui a tendance à se répandre : les modèles de langage qui produisent des chaînes de raisonnement ne savent pas vraiment raisonner. Le papier révèle des limites structurelles dès que la complexité des tâches dépasse un certain seuil. Une bonne manière de remettre l’église au centre du village.

Ce qu’on trouve dans le papier
L’étude s’intéresse aux Large Reasoning Models (LRMs), des LLMs récents (type Claude 3.7 en mode “thinking”, DeepSeek-R1, Gemini 1.5...) conçus pour expliciter une “chaîne de pensée” (Chain-of-Thought, CoT) avant de produire une réponse.
Mais Apple pose une vraie question de fond :
Est-ce que ces modèles savent résoudre un problème en plusieurs étapes logiques cohérentes ? Ou bien simulent-ils simplement un raisonnement appris ?
Pour y répondre, les chercheurs ont conçu des puzzles logiques à complexité graduelle (Tours de Hanoï, traversées de rivière, etc.), dont la difficulté peut être ajustée précisément, et où chaque étape peut être validée automatiquement grâce à un simulateur.
Ils comparent ensuite les performances des LRMs avec celles de LLMs classiques, pour des architectures équivalentes, et à budget de calcul identique.
Ce que montrent les résultats
L’analyse révèle trois régimes de comportement, selon la complexité du problème (mesurée par le nombre d’étapes minimales requises pour le résoudre) :
Sur les problèmes simples (2–5 étapes) : les LLMs classiques s’en sortent souvent mieux. Les modèles qui “raisonnent” tendent à sur-analyser, générer des étapes inutiles… et finir par se tromper.
Sur les problèmes de complexité moyenne (6–15 étapes) : les LRMs sont clairement meilleurs. Leur CoT permet de tâtonner, corriger, et converger vers une bonne solution.
Au-delà (~15–30+ étapes) : les deux types de modèles échouent. Pire : les LRMs raccourcissent leur raisonnement au lieu de l’allonger. Ils produisent moins d’étapes de réflexion à mesure que le problème devient plus difficile.
Ce phénomène est documenté : le nombre de tokens générés dans la chaîne de pensée baisse quand la complexité augmente. Comme si le modèle “renonçait” à chercher une solution complète dès qu’il pressent que l’espace de recherche devient trop grand.
Pourquoi c’est important
Ce papier apporte une clarification majeure :
“Donner plus de temps de calcul à un modèle de langage ne le rend pas meilleur raisonneur.”
La limite ne serait ni liée au temps ni au nombre de tokens, mais dans la structure même du modèle. Un LRM peut “imiter” un raisonnement, mais il ne sait pas planifier précisément des séquences longues ni suivre un algorithme jusqu’au bout.
Et surtout :
👉 Même quand on lui fournit explicitement l’algorithme (ex. celui de la Tour de Hanoï), le modèle échoue à l’appliquer correctement au-delà de 20–30 étapes. Il comprend le code, mais ne parvient pas à l’exécuter sans erreur.
L’illusion de raisonnement peut induire en erreur dans plusieurs cas :
Agents conversationnels censés planifier des actions longues (e.g. copilotes pour la programmation, assistants pour la logistique ou la manipulation de fichiers) : si la tâche demande plus de 10–15 étapes précises, le modèle va halluciner des sous-étapes, perdre le fil, ou s’arrêter prématurément.
Applications d’IA autonome : déléguer entièrement des plans complexes à un LLM est risqué sans supervision ni mécanismes correctifs.
Cas d’usage critiques = quand une séquence logique incorrecte peut produire une erreur non triviale, comme :
automatisation d’un pipeline de traitement de données ;
enchaînement d’appels d’API avec contraintes d’état ;
exécution d’une procédure métier réglementée.
Dans ces contextes, il faut hybrider :
Soit en faisant valider chaque étape par un moteur de règles ou un simulateur,
Soit en déléguant la planification à un solveur symbolique (et non au LLM),
Soit en structurant le raisonnement avec des mémoires intermédiaires vérifiables.
À retenir
Les modèles “qui pensent” n’ont pas de mécanisme de raisonnement fiable dès que la tâche dépasse ~10–15 étapes.
Leur performance décroît avec la complexité, et ils réduisent eux-mêmes leur effort de raisonnement quand ils sentent qu’ils vont échouer.
Pour des tâches impliquant un enchaînement logique long, il est impératif de coupler LLM et logique algorithmique (ou au minimum, d’instaurer des garde-fous sur le raisonnement).
2. Nouveaux modèles / outils
OpenAI
o3-pro
OpenAI déploie o3-pro, une version plus fiable et plus rigoureuse de son modèle o3, pensée pour les usages exigeants comme le code, les sciences ou l'éducation. Il est un peu plus lent que ses prédécesseurs, mais les réponses gagnent en clarté, précision et cohérence.
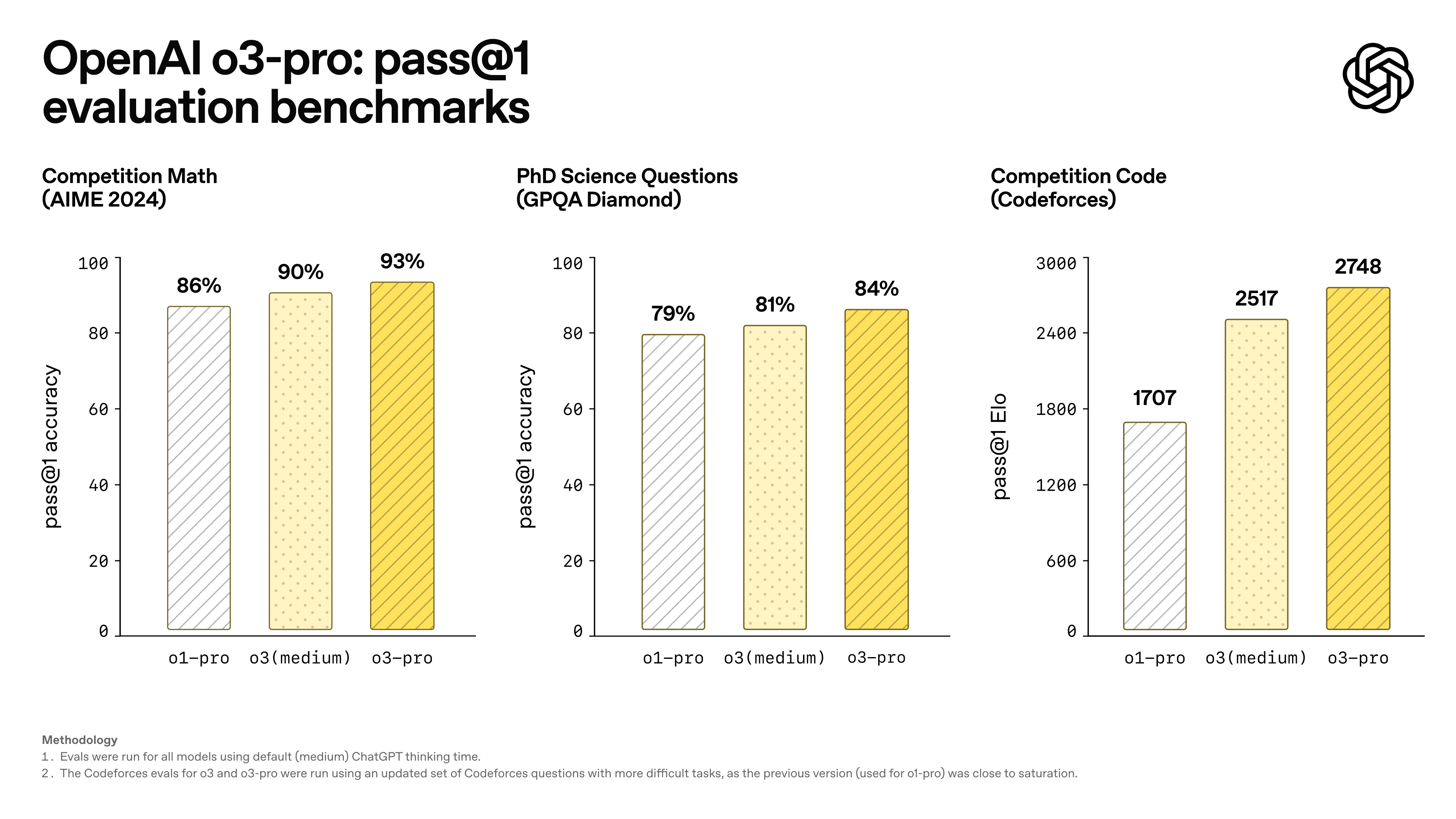
Disponible dès maintenant pour les utilisateurs Pro et Team, il remplace o1-pro. Pas encore d’images ni de Canvas, mais pour tout ce qui demande de bien réfléchir… c’est clairement le modèle à tester (si vous avez l’abonnement).
Record
OpenAI introduit Record, une nouvelle fonctionnalité (Mac uniquement, pour l’instant réservée aux abonnement Team) qui permet d’enregistrer des réunions ou notes vocales, d’en générer un résumé structuré. Les enregistrements sont indexés dans l’historiques, ce qui permet de poser des questions comme « Qu’a-t-on décidé lundi sur la roadmap ? » et d’obtenir une réponse sourcée.
Connectors
OpenAI déploie une fonctionnalité beta qui permet à ChatGPT de se connecter à vos outils (Google Drive, GitHub, SharePoint…) pour interagir directement avec vos documents ou données métiers dans le chat.
Concrètement, vous pouvez effectuer des recherches, synthétiser du contenu, ou exécuter des analyses croisées sans quitter ChatGPT. Deux modes sont proposés : la recherche rapide (pour des requêtes simples) et la recherche approfondie (pour croiser plusieurs sources internes et web avec citations).
Il est aussi possible de pré-indexer du contenu (comme des dossiers Drive) pour des réponses plus rapides, ou d'ajouter ses propres connecteurs personnalisés via le protocole MCP.
Les Pro, Team et Enterprise peuvent aussi ajouter leurs propres connecteurs. Une vraie brique vers un copilote AI connecté à votre stack.
Mistral
Mistral Code
Mistral dévoile son assistant de code pour intégrer l’IA dans les workflows des équipes tech : modèles maison (Codestral, Devstral…), plugin IDE, déploiement cloud ou on-prem, et outils d’admin pour les DSI. Dispo en bêta privée sur VSCode et JetBrains.

Google
Gemini 2.5 Pro
Google dévoile une version améliorée de son modèle Gemini 2.5 Pro, avec des gains notables sur les benchmarks (LMArena, WebDevArena, Aider Polyglot, GPQA, HLE). Il progresse en codage complexe, raisonnement, et qualité des réponses, avec un style mieux structuré et plus créatif.
Disponible dès maintenant en preview dans Google AI Studio, Vertex AI (avec budgets de calcul) et l’app Gemini. La version stable est prévue dans les prochaines semaines.

Alibaba
QwenLong-L1
QwenLong-L1 introduit une approche RL pour entraîner des modèles à mieux gérer les contextes longs. L’idée ? Partir d’un LLM entraîné sur des contextes courts, puis allonger progressivement le contexte via un curriculum-guided RL.

Manus
Manus intègre désormais Veo 3, le modèle vidéo de Google qui fait grand bruit. Les membres Basic, Plus et Pro peuvent déjà tester.
3. En vrac :
Ce que les grandes entreprises font (et ne font pas) avec l’IA en 2025
Guerre froide dans le vibe coding : Anthropic évince Windsurf de Claude 4
Claude Gov : l’IA d’Anthropic entre au service des agences de sécurité US
🤖 Ressources data science et machine learning
1. Statistical Rethinking (2024 Edition)
Richard McElreath relance son cours culte sur l’analyse de données… mais avec un focus assumé : ici, ce sont les “modèles scientifiques” qui priment.
Au programme : 10 semaines en ligne, des vidéos pré-enregistrées, une séance de discussion hebdo, et des notebooks (R, Python, Julia) pour mettre les mains dans les MCMC, modèles hiérarchiques ou processus gaussiens. L’approche est progressive, les outils modernes, et la pédagogie toujours aussi claire.
Ce projet collaboratif propose une liste de 99 exercices concrets à coder, allant des bases (régression linéaire, k-NN) à des sujets plus avancés comme le text generation avec LSTM ou le boosting.
Chaque exercice est traité comme une mini-lab : suggestion via une issue GitHub, écriture collaborative de l'énoncé, puis contribution ouverte aux solutions. Le tout est documenté, relu, amélioré et enrichi au fil du temps.
🧑🔬 Ressources deep learning et LLMs
1. CodeAgents + Structure: A Better Way to Execute Actions
Cette recherche propose de combiner la flexibilité du code exécuté avec la robustesse du format JSON structuré. Plutôt que de générer du code librement (avec tous les risques de parsing que ça implique), l’agent produit à la fois ses "pensées" et son code sous forme JSON.
Les benchmarks (SmolBench, MATH, SimpleQA…) confirment : les agents structurés dépassent les versions classiques de 2 à 7 points selon les modèles, notamment chez OpenAI et Claude. Attention cependant : les modèles trop petits ont du mal à supporter cette complexité supplémentaire, le “structure tax” peut vite peser.

🔌 Ressources MLOps
L'article propose une méthode rigoureuse pour évaluer et optimiser les pipelines RAG, en insistant sur la complexité liée à leurs multiples composants.
Il détaille les types de métriques à utiliser (Recall@k, MRR, F1…), les défis spécifiques (subjectivité, coût du feedback humain), et recommande une approche en trois temps : prétraitement (chunking, reformulation de requêtes), traitement (retriever, générateur, prompt), et post-traitement (vérification de la qualité des réponses).
🛠️ Outils
Cursor passe la seconde avec une série d’évolutions centrées sur l’automatisation et le confort dev. BugBot fait son apparition pour commenter vos PRs GitHub et proposer des correctifs en un clic dans l’éditeur. L’agent distant, jusqu’ici en accès limité, est désormais ouvert à tous.
Côté notebooks, l’agent peut maintenant modifier plusieurs cellules dans Jupyter. On voit aussi arriver Memories (en bêta), pour que Cursor retienne des infos utiles par projet. Et l’installation des serveurs MCP est simplifiée, avec un nouveau tableau de bord pour suivre vos usages.
📖 Papiers
1. Why Gradients Rapidly Increase Near the End of Training
During long-duration Large Language Model (LLM) training runs the gradient norm increases rapidly near the end of training. In this short note, we show that this increase is due to an unintended interaction between weight decay, normalization layers, and the learning rate schedule. We propose a simple correction that fixes this behavior while also resulting in lower loss values throughout training.
Merci d’avoir lu Le brief IA !